
高可用架构·硅谷篇 - (EPUB全文下载)
文件大小:1.73 mb。
文件格式:epub 格式。
书籍内容:
版权信息
书名:高可用架构·硅谷篇(第4期)
本书由北京图灵文化发展有限公司发行数字版。版权所有,侵权必究。
您购买的图灵电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
091507240605ToBeReplacedWithUserId
硅谷的高可用架构
Twitter高性能分布式日志系统架构解析
为什么需要分布式日志?
Twitter 如何考虑这个问题?
Twitter 如何基于 Apache BookKeeper 构建 DistributeLog?
DistributeLog 案例分享
Q&A
来自Google的高可用架构理念与实践
决定可用性的两大因素
高可用性方案
Q&A
Uber容错设计与多机房容灾方案
分布式系统单点故障怎么办
大面积故障怎么办
整个数据中心挂掉怎么办
Q&A
关于工程师文化的思考
硅谷的工作环境和气氛
Google的开发工具体系介绍
工作流程:质量与效率的权衡
招聘制度对公司及团队的影响
工程师文化下的创新意识与员工心态
Q&A
翻墙到Google,重新做一个快乐的小码农
给你介绍一个不一样的硅谷
Uber
Coursera
Airbnb
这次硅谷行带给我的一些影响
Q&A:
硅谷的高可用架构
Twitter高性能分布式日志系统架构解析
作者/ 郭斯杰
Twitter 高级工程师,是 Twitter 分布式日志系统 DistributedLog/BookKeeper 的主要技术负责人,同时也是 Apache BookKeeper 项目的 PMC Chair。毕业于中科院计算所,加入 Twitter 之前,就职于 Yahoo。专注于分布式消息中间件和分布式存储系统方向。
为什么需要分布式日志?
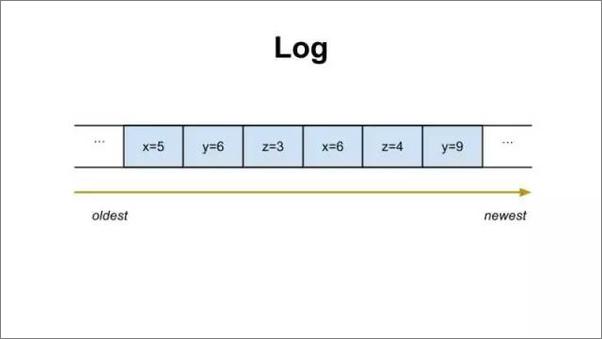
日志应该是程序员最熟悉的一种数据结构。它存在于大家每天的工作中。它是一组只追加,严格有序的记录序列。它长得像上图这个样子。日志已被证明是一种很有效的数据结构,可用来解决很多分布式系统的问题。在 Twitter,我们就用日志来解决很多有挑战的分布式系统问题。
这里主要举一个例子。我们如何使用日志在 Manhattan(Twitter的最终一致性分布式Key/Value数据库)中实现 Compare-And-Set 这样的强一致性操作。
这是一张 Manhattan 架构的简单抽象图。Manhattan 主要由 3 个组件构成,client, co-ordinator 和 replicas。Client 将请求发送给 co-ordinator,co-ordinator 找出修改键值 (key) 所对应的 replicas。然后修改 replicas。Co-ordinator 在发送请求的时候会附上相应的时间戳,replica 根据时间戳来决定最后哪个修改成功,实现最终一致性。
如果我们需要在这个最终一致性的系统上实现 CAS(Compare-And-Set) 这样的强一致性操作,会碰到什么样的问题呢?冲突!
“冲突”是什么意思呢?举个例子,假设有两个 Client,它们同时想要修改 key x,但修改成不同的结果。绿色的 Client 想将 x 从 3 修改到 4,而红色的 Client想将 x 从 3 修改到 5。
假设绿色的 Client 成功地将第一个副本从 3 修改到 4;而红色的 Client 成功地将第三个副本从 3 修改到 5。那么绿色的 Client 修改第三个副本将会失败,因为第三个副本的值已经变成了 5。同样,红色的 Client 修改第一个副本也会失败。
这是之前提到的“冲突”。因为你不知道这个系统中,x 的最终值应该是 4 还是 5。或者其他值。更严重的是,系统无法从这个“冲突”状态中恢复,也就没有最终一致性可言。
解决办法是什么呢?日志!使用日志来序列化所有的请求。使用日志后的请求流程将变成如图所示:co-ordinator 将请求写到日志中。所有的 replicas 从日志中按顺序读取请求,并修改本地的状态。
在这个例子中,修改为 4 的操作在修改为 5 的操作之前写入日志。因此,所有的副本会首先被修改成 4。那么修改为 5 的操作将会失败。
到此为止,你可以看出日志的好处。它将一个原本复杂的问题变得简单。这种解决问题的思路叫做 Pub/Sub。而日志就是 Pub/Sub 模式的基础。因为 Pub/Sub 这个模式是那么简单而且强有力,这让我们思考,是不是可以构建一个高可用的分布式日志服务,所有在 Twitter 的分布式系统都可以复用这个日志服务?
构建一个分布式日志系统,首要的事情就是找出我们需要解决什么问题,满足什么样的需求。
首先作为一个基本设施,存储在日志中的数据需要持久化,这样它可以容忍宕机,避免数据丢失。
因为需要作为分布式系统的基础设施,那么在单机上持久化是远远不够的。我们需要将数据复制到多台机器上,提高数据和系统的可用性。
当数据被复制到多台机器上的时候,我们就需要保证数据的强一致性。否则,如果我们出现丢数据、数据不一致,那么势必影响到构建在分布式日志上的所有系统。如果日志都不能相信了,你的生活还能相信谁呢 :)
Twitter 如何考虑这个问题?
为什么持久化 (durability)、多副本 (replication) 和强一致性 (consistency),对我们来说这么重要呢?
我所在 Twitter 的组,是 messaging 组。主要负责 Twitter 的消息中间件(在 Twitter 内部服务之间搬运数据),比如 Kestrel(用于在线系统)、Kafka(用于离线分析)。这些系统都不支持严格的持久化,或者在支持持久化的情况下性能极差。它们采用定期回刷 (periodic flush) 磁盘或者依赖于文件系统 (pdflush) 来持久化数据。它们因 ............
书籍插图:

以上为书籍内容预览,如需阅读全文内容请下载EPUB源文件,祝您阅读愉快。
书云 Open E-Library » 高可用架构·硅谷篇 - (EPUB全文下载)