
Hadoop实战 - (EPUB全文下载)
文件大小:3.67 mb。
文件格式:epub 格式。
书籍内容:
Hadoop实战(第2版)
陆嘉恒 著
ISBN:978-7-111-39583-6
本书纸版由机械工业出版社于2012年出版,电子版由华章分社(北京华章图文信息有限公司)全球范围内制作与发行。
版权所有,侵权必究
客服热线:+ 86-10-68995265
客服信箱:service@bbbvip.com
官方网址:www.hzmedia.com.cn
新浪微博 @研发书局
腾讯微博 @yanfabook
目 录
前言
为什么写这本书
第2版与第1版的区别
本书面向的读者
如何阅读本书
在线资源及勘误
致谢
第1章 Hadoop简介
1.1 什么是Hadoop
1.1.1 Hadoop概述
1.1.2 Hadoop的历史
1.1.3 Hadoop的功能与作用
1.1.4 Hadoop的优势
1.1.5 Hadoop应用现状和发展趋势
1.2 Hadoop项目及其结构
1.3 Hadoop体系结构
1.4 Hadoop与分布式开发
1.5 Hadoop计算模型—MapReduce
1.6 Hadoop数据管理
1.6.1 HDFS的数据管理
1.6.2 HBase的数据管理
1.6.3 Hive的数据管理
1.7 Hadoop集群安全策略
1.8 本章小结
第2章 Hadoop的安装与配置
2.1 在Linux上安装与配置Hadoop
2.1.1 安装JDK 1.6
2.1.2 配置SSH免密码登录
2.1.3 安装并运行Hadoop
2.2 在Mac OSX上安装与配置Hadoop
2.2.1 安装Homebrew
2.2.2 使用Homebrew安装Hadoop
2.2.3 配置SSH和使用Hadoop
2.3 在Windows上安装与配置Hadoop
2.3.1 安装JDK 1.6或更高版本
2.3.2 安装Cygwin
2.3.3 配置环境变量
2.3.4 安装sshd服务
2.3.5 启动sshd服务
2.3.6 配置SSH免密码登录
2.3.7 安装并运行Hadoop
2.4 安装和配置Hadoop集群
2.4.1 网络拓扑
2.4.2 定义集群拓扑
2.4.3 建立和安装Cluster
2.5 日志分析及几个小技巧
2.6 本章小结
第3章 MapReduce计算模型
3.1 为什么要用MapReduce
3.2 MapReduce计算模型
3.2.1 MapReduce Job
3.2.2 Hadoop中的Hello World程序
3.2.3 MapReduce的数据流和控制流
3.3 MapReduce任务的优化
3.4 Hadoop流
3.4.1 Hadoop流的工作原理
3.4.2 Hadoop流的命令
3.4.3 两个例子
3.5 Hadoop Pipes
3.6 本章小结
第4章 开发MapReduce应用程序
4.1 系统参数的配置
4.2 配置开发环境
4.3 编写MapReduce程序
4.3.1 Map处理
4.3.2 Reduce处理
4.4 本地测试
4.5 运行MapReduce程序
4.5.1 打包
4.5.2 在本地模式下运行
4.5.3 在集群上运行
4.6 网络用户界面
4.6.1 JobTracker页面
4.6.2 工作页面
4.6.3 返回结果
4.6.4 任务页面
4.6.5 任务细节页面
4.7 性能调优
4.7.1 输入采用大文件
4.7.2 压缩文件
4.7.3 过滤数据
4.7.4 修改作业属性
4.8 MapReduce工作流
4.8.1 复杂的Map和Reduce函数
4.8.2 MapReduce Job中全局共享数据
4.8.3 链接MapReduce Job
4.9 本章小结
第5章 MapReduce应用案例
5.1 单词计数
5.1.1 实例描述
5.1.2 设计思路
5.1.3 程序代码
5.1.4 代码解读
5.1.5 程序执行
5.1.6 代码结果
5.1.7 代码数据流
5.2 数据去重
5.2.1 实例描述
5.2.2 设计思路
5.2.3 程序代码
5.3 排序
5.3.1 实例描述
5.3.2 设计思路
5.3.3 程序代码
5.4 单表关联
5.4.1 实例描述
5.4.2 设计思路
5.4.3 程序代码
5.5 多表关联
5.5.1 实例描述
5.5.2 设计思路
5.5.3 程序代码
5.6 本章小结
第6章 MapReduce工作机制
6.1 MapReduce作业的执行流程
6.1.1 MapReduce任务执行总流程
6.1.2 提交作业
6.1.3 初始化作业
6.1.4 分配任务
6.1.5 执行任务
6.1.6 更新任务执行进度和状态
6.1.7 完成作业
6.2 错误处理机制
6.2.1 硬件故障
6.2.2 任务失败
6.3 作业调度机制
6.4 Shuffle和排序
6.4.1 Map端
6.4.2 Reduce端
6.4.3 shuffle过程的优化
6.5 任务执行
6.5.1 推测式执行
6.5.2 任务JVM重用
6.5.3 跳过坏记录
6.5.4 任务执行环境
6.6 本章小结
第7章 Hadoop I/O操作
7.1 I/O操作中的数据检查
7.2 数据的压缩
7.2.1 Hadoop对压缩工具的选择
7.2.2 压缩分割和输入分割
7.2.3 在MapReduce程序中使用压缩
7.3 数据的I/O中序列化操作
7.3.1 Writable类
7.3.2 实现自己的Hadoop数据类型
7.4 针对Mapreduce的文件类
7.4.1 SequenceFile类
7.4.2 MapFile类
7.4.3 ArrayFile、SetFile和BloomMapFile
7.5 本章小结
第8章 下一代MapReduce:YARN
8.1 MapReduce V2设计需求
8.2 MapReduce V2主要思想和架构
8.3 MapReduce V2设计细节
8.4 MapRedu ............
书籍插图:
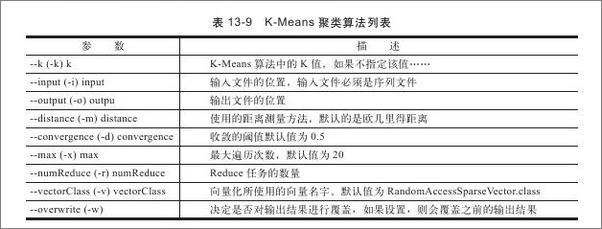
以上为书籍内容预览,如需阅读全文内容请下载EPUB源文件,祝您阅读愉快。
书云 Open E-Library » Hadoop实战 - (EPUB全文下载)