
精通Python爬虫框架Scrapy - (EPUB全文下载)
文件大小:4.95 mb。
文件格式:epub 格式。
书籍内容:
目 录
版权信息
版权声明
内容提要
关于作者
关于审稿人
前言
第1章 Scrapy简介
1.1 初识Scrapy
1.2 喜欢Scrapy的更多理由
1.3 关于本书:目标和用途
1.4 掌握自动化数据爬取的重要性
1.4.1 开发健壮且高质量的应用,并提供合理规划
1.4.2 快速开发高质量最小可行产品
1.4.3 Google不会使用表单,爬取才能扩大规模
1.4.4 发现并融入你的生态系统
1.5 在充满爬虫的世界里做一个好公民
1.6 Scrapy不是什么
1.7 本章小结
第2章 理解HTML和XPath
2.1 HTML、DOM树表示以及XPath
2.1.1 URL
2.1.2 HTML文档
2.1.3 树表示法
2.1.4 你会在屏幕上看到什么
2.2 使用XPath选择HTML元素
2.2.1 有用的XPath表达式
2.2.2 使用Chrome获取XPath表达式
2.2.3 常见任务示例
2.2.4 预见变化
2.3 本章小结
第3章 爬虫基础
3.1 安装Scrapy
3.1.1 MacOS
3.1.2 Windows
3.1.3 Linux
3.1.4 最新源码安装
3.1.5 升级Scrapy
3.1.6 Vagrant:本书中运行示例的官方方式
3.2 UR2IM——基本抓取流程
3.2.1 URL
3.2.2 请求和响应
3.2.3 Item
3.3 一个Scrapy项目
3.3.1 声明item
3.3.2 编写爬虫
3.3.3 填充item
3.3.4 保存文件
3.3.5 清理——item装载器与管理字段
3.3.6 创建contract
3.4 抽取更多的URL
3.4.1 使用爬虫实现双向爬取
3.4.2 使用CrawlSpider实现双向爬取
3.5 本章小结
第4章 从Scrapy到移动应用
4.1 选择手机应用框架
4.2 创建数据库和集合
4.3 使用Scrapy填充数据库
4.4 创建手机应用
4.4.1 创建数据库访问服务
4.4.2 创建用户界面
4.4.3 将数据映射到用户界面
4.4.4 数据库字段与用户界面控件间映射
4.4.5 测试、分享及导出你的手机应用
4.5 本章小结
第5章 迅速的爬虫技巧
5.1 需要登录的爬虫
5.2 使用JSON API和AJAX页面的爬虫
5.2.1 在响应间传参
5.3 30倍速的房产爬虫
5.4 基于Excel文件爬取的爬虫
5.5 本章小结
第6章 部署到Scrapinghub
6.1 注册、登录及创建项目
6.2 部署爬虫与计划运行
6.3 访问item
6.4 计划定时爬取
6.5 本章小结
第7章 配置与管理
7.1 使用Scrapy设置
7.2 基本设置
7.2.1 分析
7.2.2 性能
7.2.3 提前终止爬取
7.2.4 HTTP缓存和离线运行
7.2.5 爬取风格
7.2.6 feed
7.2.7 媒体下载
7.2.8 Amazon Web服务
7.2.9 使用代理和爬虫
7.3 进阶设置
7.3.1 项目相关设置
7.3.2 Scrapy扩展设置
7.3.3 下载调优
7.3.4 自动限速扩展设置
7.3.5 内存使用扩展设置
7.3.6 日志和调试
7.4 本章小结
第8章 Scrapy编程
8.1 Scrapy是一个Twisted应用
8.1.1 延迟和延迟链
8.1.2 理解Twisted和非阻塞I/O——一个Python故事
8.2 Scrapy架构概述
8.3 示例1:非常简单的管道
8.4 信号
8.5 示例2:测量吞吐量和延时的扩展
8.6 中间件延伸
8.7 本章小结
第9章 管道秘诀
9.1 使用REST API
9.1.1 使用treq
9.1.2 用于写入Elasticsearch的管道
9.1.3 使用Google Geocoding API实现地理编码的管道
9.1.4 在Elasticsearch中启用地理编码索引
9.2 与标准Python客户端建立数据库接口
9.2.1 用于写入MySQL的管道
9.3 使用Twisted专用客户端建立服务接口
9.3.1 用于读写Redis的管道
9.4 为CPU密集型、阻塞或遗留功能建立接口
9.4.1 处理CPU密集型或阻塞操作的管道
9.4.2 使用二进制或脚本的管道
9.5 本章小结
第10章 理解Scrapy性能
10.1 Scrapy引擎——一种直观方式
10.1.1 级联队列系统
10.1.2 定义瓶颈
10.1.3 Scrapy性能模型
10.2 使用telnet获得组件利用率
10.3 基准系统
10.4 标准性能模型
10.5 解决性能问题
10.5.1 案例 #1:CPU饱和
10.5.2 案例 #2:代码阻塞
10.5.3 案例 #3:下载器中的“垃圾”
10.5.4 案例 #4:大量响应或超长响应造成的溢出
10.5.5 案例 #5:有限/过度item并发造成的溢出
10.5.6 案例 #6:下载器未充分利用
10.6 故障排除流程
10.7 本章小结
第11章 使用Scrapyd与实时分析进行分布式爬取
11.1 房产的标题是如何影响价格的
11.2 Scrapyd
11.3 分布式系统概述
11.4 爬虫和中间件的变化
11.4.1 索引页分片爬取
11.4.2 分批爬取URL
11.4.3 从设置中获取初始URL
11.4.4 在Scrapyd服务器中部署项目
11.5 创建自定义监控命令
11.6 使用Apache Spark流计算偏移量
11.7 运行分布式爬取
11.8 系统性能
11.9 关键要点
11.10 本章小结
附录A 必备软件的安装与故障排除
欢迎来到异步社区!
版权信息书名:精通Python爬虫框架ScrapyISBN:978-7-115-47420-9本书由人民邮电出版社发行数字版。版权所有,侵权必究。您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以 ............
书籍插图:

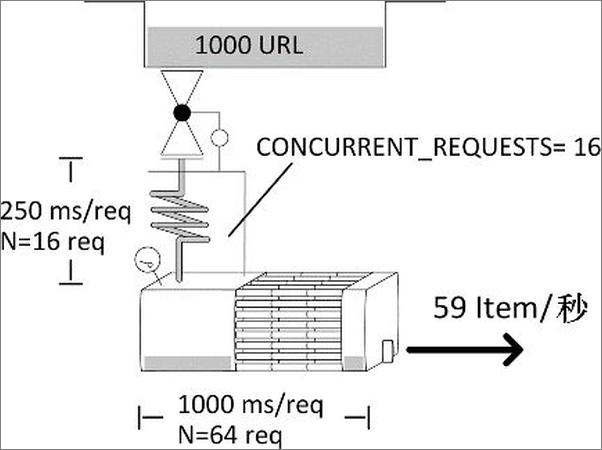
以上为书籍内容预览,如需阅读全文内容请下载EPUB源文件,祝您阅读愉快。
书云 Open E-Library » 精通Python爬虫框架Scrapy - (EPUB全文下载)